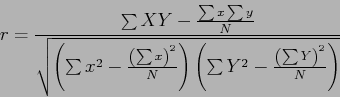Next: Aprendizaje no supervisado:K-mean Up: Procesamiento del lenguaje natural Previous: El proceso de preparación
Para poder encontrar grupos de forma no supervisada, en base a los intereses de los diferentes miembros de los pueblos originarios norteamericanos, utilizamos en primero momento el algoritmo jerárquico, propuesto por vez primera por S.C. Johnson en 1967.
Partimos de ![]() elementos que serán agrupados en
elementos que serán agrupados en ![]() grupos (o clusters).
Cada cluster calculará su distancia con respecto a otro cluster
en base a sus similitudes agrupadas en una matriz de frecuencia de
palabras. Para darnos una idea de la lógica de este procedimiento.
( Ver algoritmo
grupos (o clusters).
Cada cluster calculará su distancia con respecto a otro cluster
en base a sus similitudes agrupadas en una matriz de frecuencia de
palabras. Para darnos una idea de la lógica de este procedimiento.
( Ver algoritmo ![]() .7
.7
Para el cálculo de las distancias, se utilizó en este trabajo una matriz de frecuencia de palabras, calculando la distancia mediante Coeficiente de Correlación de Pearson que vemos en la ecuación (1)8
Sin embargo, el algoritmo presenta limitantes: su complejidad es por
lo menos
![]() , donde
, donde ![]() es el número total de
elementos y no se puede deshacer un agrupamiento realizado.
es el número total de
elementos y no se puede deshacer un agrupamiento realizado.
julio 2010-03-26